

我们可以通过一个比喻来解释什么是行为风险识别:自动驾驶的机器大脑在参加一场考试,他遇到一道难题,在两个答案之间犹豫不决。尽管这道难题他不会做,但我们可以通过许多方式得知他“拿不准”这件事本身,例如题目描述的场景复杂或者之前不熟悉,并进一步针对这道题目请求“人类教练”的帮助。
我们人类在开车的时候,会由眼睛和耳朵等“传感器”完成对环境信息的探测和感知,然后这些信息传入我们的大脑,大脑经过所有的处理之后,发出直接的动作指令给“控制器“——我们的手和脚。
对于人类大脑的工作过程,我们还所知有限。而在当前的自动驾驶技术中,有一种尝试是“端到端”技术,也就是完全模拟我们的大脑,试图直接将传感器获得的环境信息输入深度神经网络,直接输出对车辆的控制信号。
这类方法存在一个最大的问题就是深度神经网络缺乏可解释性。当遇到未知的场景时,我们无法保障网络输出结果的安全性。因此,当前绝大部分自动驾驶企业还是采用分层和解耦的思路,来解决自动驾驶决策的问题。
在这种思路下,自动驾驶的大脑工作由决策规划模块来完成(更多详细内容可参考之前的技术文章):

图1. 自动驾驶系统中的决策规划模块分层结构
如图1所示,典型的决策规划模块可以分为三个层次。其中,全局路径规划(Route Planning)在接收到一个给定的行驶目的地之后,结合地图信息,生成一条全局的路径,作为为后续具体路径规划的参考;行为决策层(Behavioral Layer)在接收到全局路径后,结合从感知模块得到的环境信息(包括其他车辆与行人,障碍物,以及道路上的交通规则信息),以及从预测模块得到的障碍物未来可能行驶轨迹信息,作出具体的行为决策(例如选择变道超车还是跟随);最后,运动规划(Motion Planning)层根据具体的行为决策,规划生成一条满足特定约束条件(例如车辆本身的动力学约束、避免碰撞、乘客舒适性等)的轨迹,该轨迹作为控制模块的输入决定车辆最终行驶路径。
通过上面的介绍我们已经知道,机器大脑通过分层的方法来降低问题难度。在目前的技术发展阶段,全局路径规划和运动规划这两个部分的方案已经相对比较成熟。这一方面也是由于这两层的任务目标十分明确(我们的行驶目的地是确定的;运动规划需要满足的约束条件也是确定的)。
而在行为决策层,我们需要面对的则是一系列不确定性的输入信息。这种不确定性的来源主要有两大部分:
一部分来自环境,因为我们的物理世界本身就是在不断变化的,环境中其他交通参与者未来的行为我们无法明确得知(预测模块的任务就是降低这一类不确定性)
另一部分来自传感器在采集和处理环境信息的时候(将物理世界在数字世界中建模),不可避免地需要进行采样等离散化处理,这样就导致真实物理世界的连续信息有一部分损失,同时也会产生空间上的误差和时间上的延迟。
与之相对的是,行为决策层的输出却必须是确定性的结果,具体来说,这些输出通常包括:
综合决策(主车的综合决策行为,如换道意图和借道意图)
个体决策(主车对单个障碍物做出的决策,如绕行和减速避让)
用严格一些的语言来说,下游运动规划层需要生成具体的行驶轨迹,在数学上这是一个非凸优化问题,难以直接求解,因此行为决策需要将运动规划的解空间进行限定,保证运动规划模块的求解高效性和稳定性。
在处理这些输入不确定性,并输出确定性决策的过程中。我们需要考虑的目标是多样化的,不仅仅包括安全性,还要考虑交通规则、决策稳定性,车辆模型,甚至还要求无人车的行为需要符合人类驾驶习惯(环境中存在大量与人类参与者的交互)。
我们需要将这些多目标转换为机器容易理解和处理的方式,具体手段包括:
约束目标:将碰撞避免、交通规则等目标转换为不可以违反的边界条件。
优化目标:对一些软性的目标(通行效率、舒适性等)设置不同权重的损失惩罚函数。
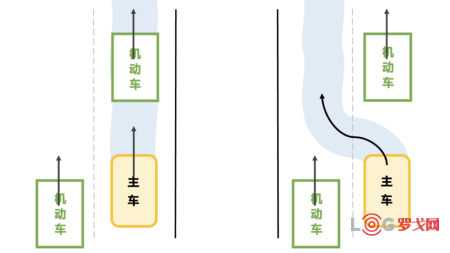
由于输入信息的不确定性,我们的机器大脑在实际中常常面临“两难”的局面。例如下图这样十分常见的一种场景,选择减速跟车还是换道超车。前者会影响通行效率,而后者则可能带来更高的风险(旁边车道来车)。

图2. 常见的一种行为决策场景:减速or变道
而实际的场景更为复杂多变,并且一定会出现长尾场景,每一种行为决策的选择都不可能完全避免未来的风险,决策输出的多目标求解过程无法保证每次都得到最低风险的结果。因此,我们需要在行为决策层增加一种以安全性为单目标的算法模型,希望能够对可能发生的风险进行提前的识别,当安全性不满足要求时采用人工接管或保守策略。
读者可能提出的一个问题是:如果能够建立这样的风险识别模型,那不就可以作出最安全的行为决策了吗?这个问题的答案其实就是在“知道正确答案”和“知道不会做”二者之间其实是存在一个gap的。在预期功能安全国际标准(ISO/PAS 21448)中,场景(scenarios)被划分为如下图所示的4个区间,分别为(1)已知-安全、(2)已知-不安全、(3)未知-不安全和(4)未知-安全。最终的目标是尽可能缩小位于区间(2)和(3)中的场景(scenarios)比例,即将确保场景(scenarios)控制在安全的区间。而行为风险识别希望达到的目的就是将区间(3)中的场景首先转化为区间(2),即“know unknowns”。接下来,随着行为决策本身算法能力的不断提升(越来越见多识广),才能够将更多的区间(2)场景转化为区间(1)。

图3. 国际标准ISO/PAS 21448中对场景(scenarios)的分类
无人车行为决策模块面对的是高不确定性的动态场景。在当前技术阶段,存在算法能力的覆盖边界。在边界上存在的长尾问题是最难解决的一类问题,同时也是最危险的场景。在我们的自动驾驶算法不断进步,不断扩大能力边界的同时,我们也希望通过对行为决策模块各种指标进行在线监控,同时结合周围环境信息,希望从这些“蛛丝马迹”中提前识别出危险场景。然后对算法结果进行反馈,并向人类安全员发出提醒。
行为风险识别的具体算法,以及识别后的处理方式,将在下次技术解析中详细介绍。


共探AI时代的供应链数智化发展之路!《数智化供应链白皮书》正式发布
1566 阅读
外卖战OR即配战?京东美团博弈,快递受伤?
1470 阅读
零售企业仓储博弈:自营VS外包
1307 阅读4个低碳奖项丨2025 LOG低碳供应链&物流创新案例申报开启!
1173 阅读顺丰再出手,领投无人车公司「白犀牛」
1000 阅读外贸出口转内销商家在抖音电商成交3.6亿元
924 阅读5000种汽车配件丝滑入仓,菜鸟海外仓推出汽配出海解决方案
807 阅读快递绿色包装进校园,极兔全方位展示全链路绿色管理成果
738 阅读投资12.5亿元!京东物流、胖东来联手布局供应链产业基地
804 阅读小红书与淘宝天猫达成战略合作:种草全链路方案升级
677 阅读







粤公网安备 44030402005698号


 [罗戈导读]无人车行为决策模块面对的是高不确定性的动态场景。
[罗戈导读]无人车行为决策模块面对的是高不确定性的动态场景。















